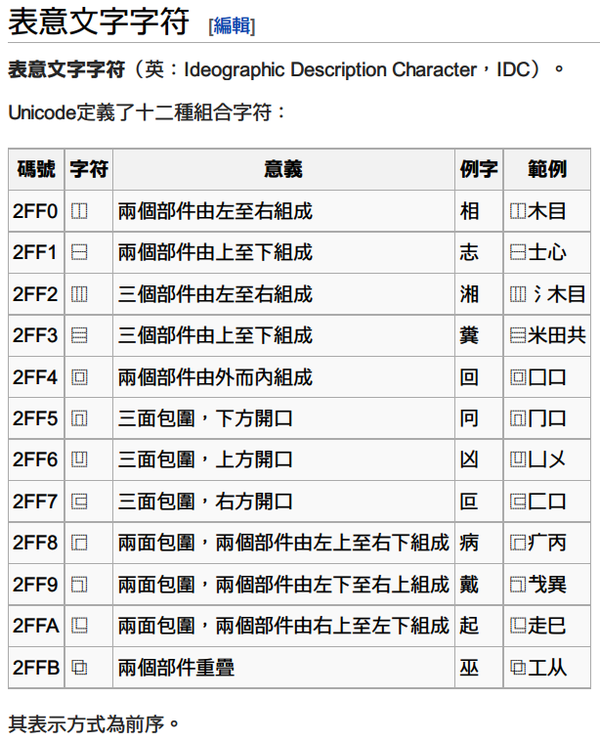
目 前大部分的汉字字符集(包括 Unicode),对于汉字编码的处理大致为先搜集汉字,给予每个汉字一个数字编码。然而,汉字数量庞大,往往字集不完全。再加上汉字本身具有组合以及开 放的特性,汉字使用者很有可能自造新字,因此不可能有一个字集可以搜集到所有汉字。[2]
基于这种考虑,Unicode 组织在 3.0 版本开始,对 CJKV 统一表意文字做了一个新的支持——表意文字描述序列(Ideographic Description Sequences,以下简称IDS)。其目的是利用十二种组合字符,来描述所定义的汉字内部构字部件的相对位置,从而精确表示生僻字(或未被电脑字符集收入的缺字)。
如果大家有关注「生僻字」话题的话,应该会注意到这些题目的风格都很接近(都使用了「⿰⿱⿲⿳⿴⿵⿶⿷⿸⿹⿺⿻」等符号来表示生僻字)。这十二个符号的名字叫做「表意文字描述字符」(Ideographic Description Characters,以下简称IDC)。
其使用方法如下:
 那么有人或许要问,如果我所要表示的汉字的构字部件不止两个怎么办呢?
那么有人或许要问,如果我所要表示的汉字的构字部件不止两个怎么办呢?
没关系,我们可以继续往下扩写,类似 1×2÷3+4-5 这样的数学运算表达式。这种表达式就是笔者前文提到的 IDS 。其中构字部件相当于数学运算表达式中的数字和未知数,十二种 IDC 相当于数学运算表达式中的算术运算符。就像下面这样:
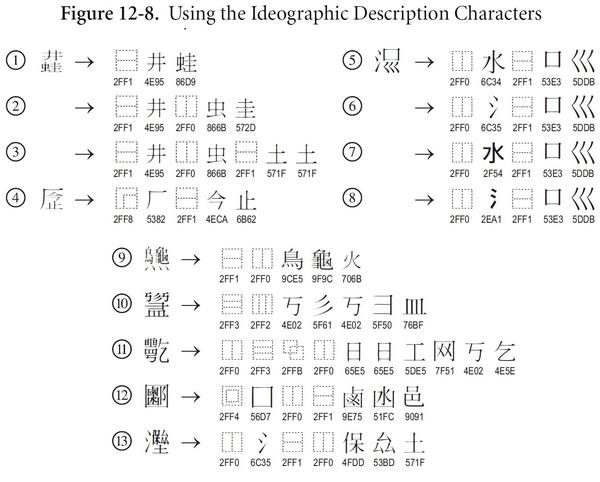 (注意:此处 Figure 12-8 来自 Unicode 6.2.0 官方文档(见参考文献 4 )。例 10 裏面的⿲(U+2FF2)和⿳(U+2FF3)用反的问题已经修复。感谢@舰队街 Todd@席祯@摩山等细心读者的指正。 同时也感谢@梁海 先生的意见。)
(注意:此处 Figure 12-8 来自 Unicode 6.2.0 官方文档(见参考文献 4 )。例 10 裏面的⿲(U+2FF2)和⿳(U+2FF3)用反的问题已经修复。感谢@舰队街 Todd@席祯@摩山等细心读者的指正。 同时也感谢@梁海 先生的意见。)
这里还要注意两个细节:
- 十二种 IDC 之间没有优先级顺序。(优先级顺序相当于算术运算符中的先乘除,後加减。当然你了解蛋疼的 C 语言运算符优先级顺序更好。)
- IDC 与构字部件是通过波兰表达式(前缀表达式)构造成 IDS 的。(下面会讲到。或者你点击超级链接进去了解一下。码农同志应该都会的。)
如上图例 4 所示,用前缀表达式构造的 IDS ⿸厂⿰今止 相当于 ⿸厂(⿰今止) 。即先对「今」和「止」做上下结构的拼合,再对这个拼合部件与「厂」做左上方的半包围拼合。将这个 IDS 转换成普通的中缀表达式应该是 厂⿸(今⿰止) 。
另外,汉字构字部件拆分的粒度完全由你自己决定,只要你觉得能表示到位就可以。如上图的例 1、2、3 以及例 5、6、7、8 各自表示同一个汉字。(就像算术表达式 1+2 与 1+(1+1) 等价一样)
接着我们来实练一次吧。

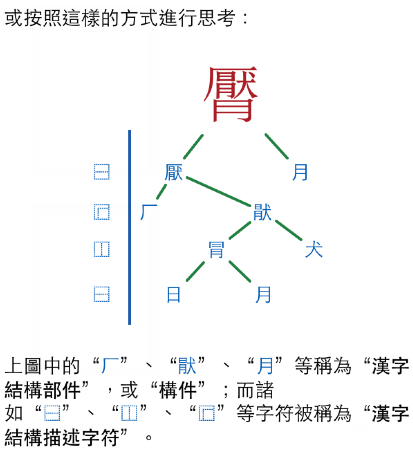 (以上截图来自 iOS 应用——《康熙字典》)
(以上截图来自 iOS 应用——《康熙字典》)
最後布置一个课後作业,本文章最开头题图中出现的「biang」字,用 IDS 表示出来应该是什么样子?(答案可参考下头的参考文献 6 、7。)
下课。
————————————————————
参考文献:
[1]: 独体字一定是独体字结构吗?怎么「臣」字是独体字,却是半包围结构?
[2]: http://zh.wikipedia.org/zh-hk/表意文字描述序列
[3]: Chinese character description languages
[4]: http://www.unicode.org/versions/Unicode6.2.0/ch12.pdf, Page 423~425
[5]: http://zh.wikipedia.org/zh-hk/波蘭表示法
[6]: IDS + OpenType: Pseudo-encoding Unencoded Glyphs, 小林劍(Ken Lunde)
[7]: Biángbiáng麵
来自http://zhuanlan.zhihu.com/hanzi/19753292